
Deploying Zookeeper Cluster


This is a third article in our Running Kafka in Kubernetes publication. Refer to https://medium.com/kafka-in-kubernetes/automating-storage-provisioning-41034e570928 to see the previous article.
Motivation
Kafka uses Zookeeper to manage service discovery for Kafka Brokers that form the cluster. Zookeeper sends changes of the topology to Kafka, so each node in the cluster knows when a new broker joined, a Broker died, a topic was removed or a topic was added, etc.. In short, Zookeeper is the manager of Kafka operation.
Deploying the Zookeeper
Zookeeper is deployed using YAML. You can refer to this https://raw.githubusercontent.com/fernandocyder/k8s-practice/master/04.kafka-expose-service/01.zookeeper.yaml on how we deploy the Zookeeper.
There are few key points that make this deployment working.
First, we deploy using StatefulSet
kind: StatefulSet
metadata:
name: zookeeper
namespace: kafka
spec:
serviceName: zookeeper
replicas: 3
updateStrategy:
type: RollingUpdate
podManagementPolicy: OrderedReady
selector:
matchLabels:
app: zookeeper
template:
metadata:
labels:
app: zookeeper
spec:
initContainers:
- command:
- /bin/sh
- -c
- |-
set -ex;
mkdir -p "$ZOO_DATA_LOG_DIR" "$ZOO_DATA_DIR" "$ZOO_CONF_DIR";
if [[ ! -f "$ZOO_DATA_DIR/myid" ]]; then
IDX="$(echo $HOSTNAME| rev | cut -d "-" -f1 | rev)"
SVR_INDEX=$((IDX+1))
echo $SVR_INDEX > "$ZOO_DATA_DIR/myid"
fi
env:
- name: HOSTNAME
valueFrom:
fieldRef:
fieldPath: metadata.name
envFrom:
- configMapRef:
name: zookeeper-config
image: busybox:1.28
imagePullPolicy: IfNotPresent
name: zookeeper-init
securityContext:
runAsUser: 0
volumeMounts:
- mountPath: /data
name: data
containers:
- image: zookeeper
imagePullPolicy: Always
name: zookeeper
ports:
- containerPort: 2181
name: client
- containerPort: 2888
name: server
- containerPort: 3888
name: leader-election
resources: {}
envFrom:
- configMapRef:
name: zookeeper-config
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /data
name: data
- mountPath: /datalog
name: datalog
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: nfs-client
resources:
requests:
storage: 100Mi
- metadata:
name: datalog
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: nfs-client
resources:
requests:
storage: 100MiHere is what the above statefulset does:
- Set 3 replicas.
- Each Pod has init and main container. The init container is responsible for defining the zookeeper node unique ID. Thanks for StatefulSet, the hostname of each Pod is always fixed and has index number suffix, for example: zookeeper-0, zookeeper-1, etc..
- Define volume claim template using ‘nfs-client’ storage class and mount two volumes.
Next, define the config map which is attached to the StatefulSet Pod environment variables.
kind: ConfigMap
metadata:
name: zookeeper-config
namespace: kafka
data:
ZOO_DATA_LOG_DIR: "/datalog"
ZOO_DATA_DIR: "/data"
ZOO_CONF_DIR: "/conf"
ZOO_SERVERS: "server.1=zookeeper-0.zookeeper:2888:3888;2181 server.2=zookeeper-1.zookeeper:2888:3888;2181 server.3=zookeeper-2.zookeeper:2888:3888;2181"The above environment variables are used by the docker-entrypoint.sh file used by the zookeeper docker.
Notice this variable: ZOO_SERVERS: “server.1=zookeeper-0.zookeeper:2888:3888;2181 server.2=zookeeper-1.zookeeper:2888:3888;2181 server.3=zookeeper-2.zookeeper:2888:3888;2181”
The above host names are valid as we deploy Zookeeper using StatefulSet and have Headless Service.
What is Headless Service? Refer to https://kubernetes.io/docs/concepts/services-networking/service/#headless-services.
You can use a headless Service to interface with other service discovery mechanisms, without being tied to Kubernetes’ implementation. For headless Services, a cluster IP is not allocated, kube-proxy does not handle these Services, and there is no load balancing or proxying done by the platform for them.
Here is the YAML to create the Headless Service
kind: Service
metadata:
name: zookeeper
namespace: kafka
labels:
app: zookeeper
spec:
ports:
- port: 2888
name: server
- port: 3888
name: leader-election
- port: 2181
name: client
clusterIP: None
selector:
app: zookeeperDeploy the StatefulSet
Simply deploy the above Zookeeper YAML in ‘kafka’ namespace. You can see here in Rancher
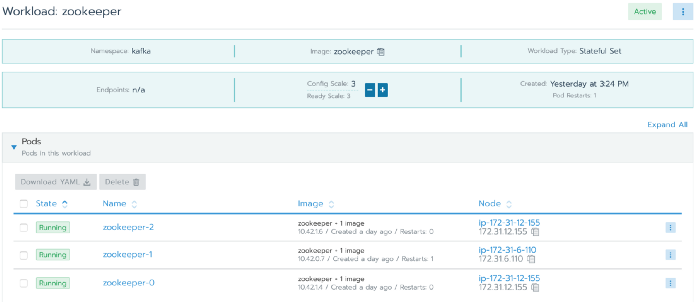
Conclusion
Now, our Zookeeper service is up and running.
In this article, you have seen how we deploy 3 replicas of a Zookeeper cluster in K8S.