Custom Kafka SinkConnector for ElasticSearch


Motivation
We have some applications running on Rancher Kubernetes platform and we have configured the Kubernetes containers logs to be shipped to Kafka Topics. Right now, we are going to developed a custom Kafka SinkConnector to parse the log records from Kafka Topics to ElaksticSearch.
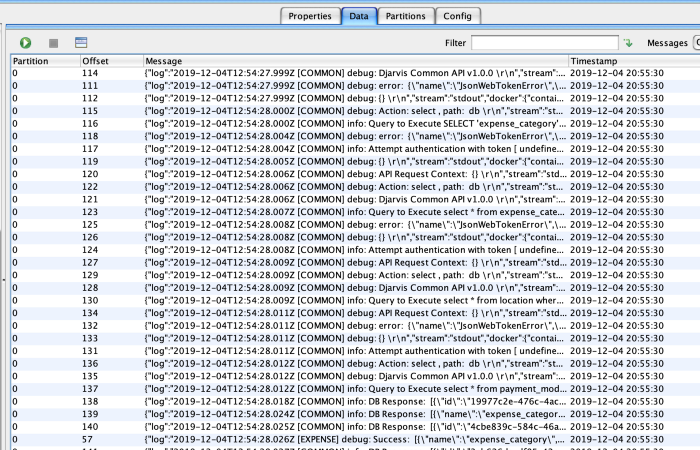
First we need to identity which topics and what kind of message content that we have. We inspect some messages in our Topic using Kafka Tool and here is the content.
Create SinkConnector Maven Project
SinkConnector in Kafka (powered by Confluent) is developed on Java. Let’s start a new Maven project for this, by invoking this command.
mvn archetype:generate -DgroupId=sg.com.cyder.kafka.log.elk -DartifactId=cyderkafka-elk-sink -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
Develop Connector and Task
Let’s complete the project. The full source code can be found here https://github.com/CyderSG/kafka-elk-sink.
Let’s take a look at the some key classes.
ElkSinkConnector
This class (https://github.com/CyderSG/kafka-elk-sink/blob/master/src/main/java/sg/com/cyder/kafka/log/elk/sink/ElkSinkConnector.java) is the main entry for the SinkConnector. It defines the Task Definition and refers to the ElkSinkTask class as the Class to execute the task.
ElkSinkTask
This class (https://github.com/CyderSG/kafka-elk-sink/blob/master/src/main/java/sg/com/cyder/kafka/log/elk/sink/ElkSinkTask.java) does the main heave-lifting job.
Here is the main method, put(). This method basically get the list of records from Kafka broker (well, this SinkConnector acts as Kafka Consumer too). After getting the records from Kafka broker, it sends to Elastics Search service.
public void put(Collection < SinkRecord > collection) {
try {
log.debug("Put [" + collection + "]");
Collection < String > recordsAsString = collection.stream().map(r - > String.valueOf(r.value())).collect(Collectors.toList());
log.debug("Records [" + recordsAsString + "]");
elasticService.process(recordsAsString);
} catch (Exception e) {
log.error("Error while processing records");
log.error(e.toString());
}
}
ElkServiceImpl
Let’s take a look at this class (https://raw.githubusercontent.com/CyderSG/kafka-elk-sink/master/src/main/java/sg/com/cyder/kafka/log/elk/sink/elkservice/ElkServiceImpl.java). The process() method is responsible for processing each message (assumed in JSON format), filtering them, and sending them to the ELK server.
List < Record > recordList = new ArrayList < > ();
recordsAsString.forEach(recordStr - > {
try {
log.debug("Verifying record [" + recordStr + "]");
if (recordStr.matches(".*\\[.*\\].*")) {
log.debug("Processing record [" + recordStr + "]");
JsonObject recordAsJson = gson.fromJson(recordStr, JsonObject.class);
String behavior = Constants.insertedFlagValue;
recordList.add(new Record(recordAsJson, behavior));
}
} catch (JsonSyntaxException e) {
log.error("Cannot deserialize json string, which is : " + recordStr);
} catch (Exception e) {
log.error("CYDER: Cannot process data, which is : " + recordStr + ", with error [" + e.getMessage() + "]");
}
});
try {
elasticClient.bulkSend(recordList, indexName, typeName);
} catch (Exception e) {
log.error("Something failed, here is the error:");
log.error(e.toString());
}
}Deploy the Connector
Development is done, code is ready. Now, we need to deploy the code to CP / Kafka Connect. We assumed that the Kafka Connect server is ready with the running REST API.
So, firstly we package this code as JAR file, and copy the JAR file, including the dependencies into the Connect plugin path.
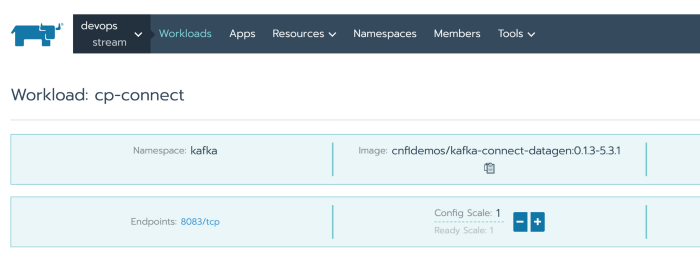
We use Rancher, and this is our Kafka Connect workload
The plugin path is configured as Workload environment variable
CONNECT_PLUGIN_PATH=/usr/share/java,/usr/share/confluent-hub-components,/plugins
This is the path and content of the plugin folder (viewed in Rancher console)
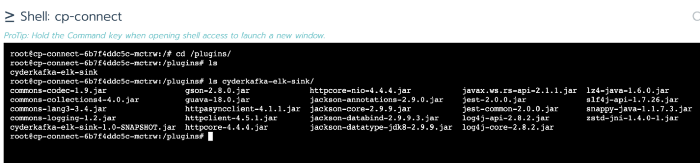
After copying the JAR files, you need to reload the Workload. And of course, you need to reload the Workload every time there is an update of the JAR file.
Create the Connector in Kafka Connect
JAR files are ready, deployed. The next thing to do is register / create the connector. Use the following CURL command to create one
curl -v -H "Content-Type: application/json" -X POST --data "@elksink.json" http://xxx:8083/connectors
This is the sample of the elksink.json file
"name": "cyder-elk-sink-connector",
"config": {
"connector.class": "sg.com.cyder.kafka.log.elk.sink.ElkSinkConnector",
"tasks.max": "1",
"type.name": "type.name",
"elastic.url": "xxx",
"elastic.port": 9200,
"index.name": "cyderdev-log",
"flag.field": "status",
"data.array": "dataList",
"topics": "djarvis-dev-log",
"value.converter": "org.apache.kafka.connect.storage.StringConverter",
"key.converter.schemas.enable": false,
"value.converter.schemas.enable": false,
"key.converter": "org.apache.kafka.connect.storage.StringConverter"
}
}After creating it, check the connector is added by invoking this CURL
curl -v -X GET http://xxx:8083/connectors
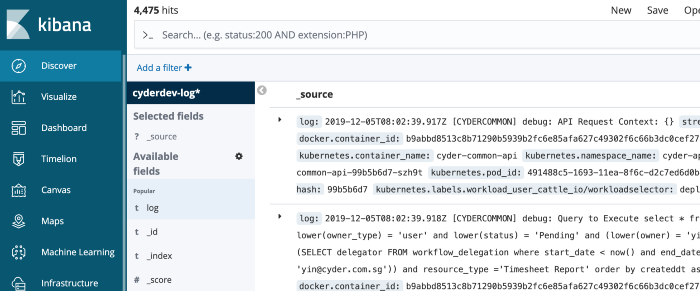
Check in Kibana
Well, assumed everything is fine, finally we can see the search index in Kibana ELK.